Make-An-Audio: Text-To-Audio Generation with Prompt-Enhanced Diffusion Models
Make-An-Audio
Introduction
文章指出由于Text-Audio pair数据的匮乏及音频数据的复杂性(每秒16kHz的采样率下,有16000个数据点),导致在多模态生成任务重,文本到音效的合成进展有效。随后在文章中提出针对这两个问题的解决方法:
- Pseudo Prompt Enhancement: Distill-then-Reprogram
- Spectrogram autoencoder
随后将text-to-audio推广到任意模态到音频
Pseudo Prompt Enhancement: Distill-then-Reprogram
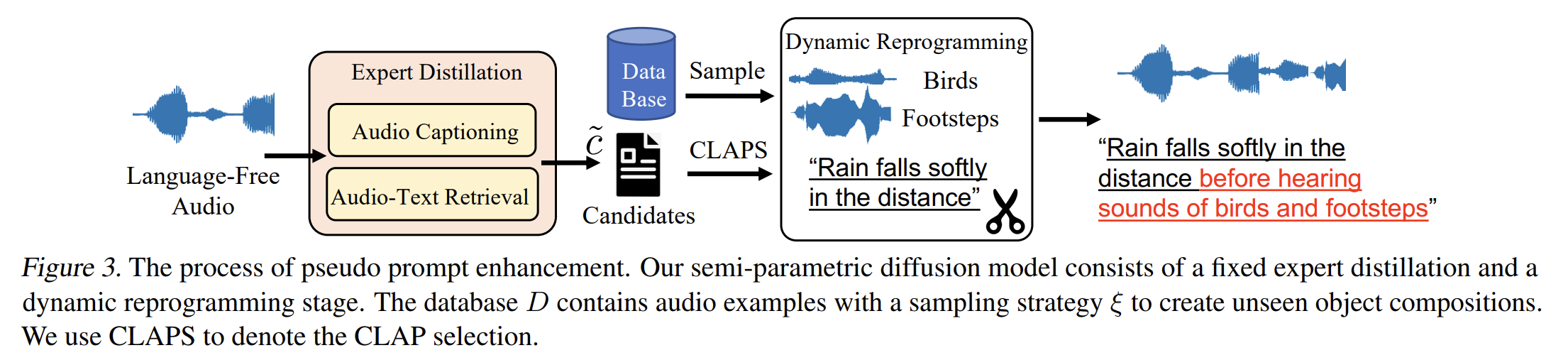
Expert 1: A CRNN-GRU BASED REINFORCEMENT LEARNING APPROACH TO AUDIO CAPTIONING
给音频加字幕的
Expert 2: AUDIO RETRIEVAL WITH WAVTEXT5K AND CLAP TRAINING
跨模态检索的
评委:CLAP:clap: : LEARNING AUDIO CONCEPTS FROM NATURAL LANGUAGE SUPERVISION
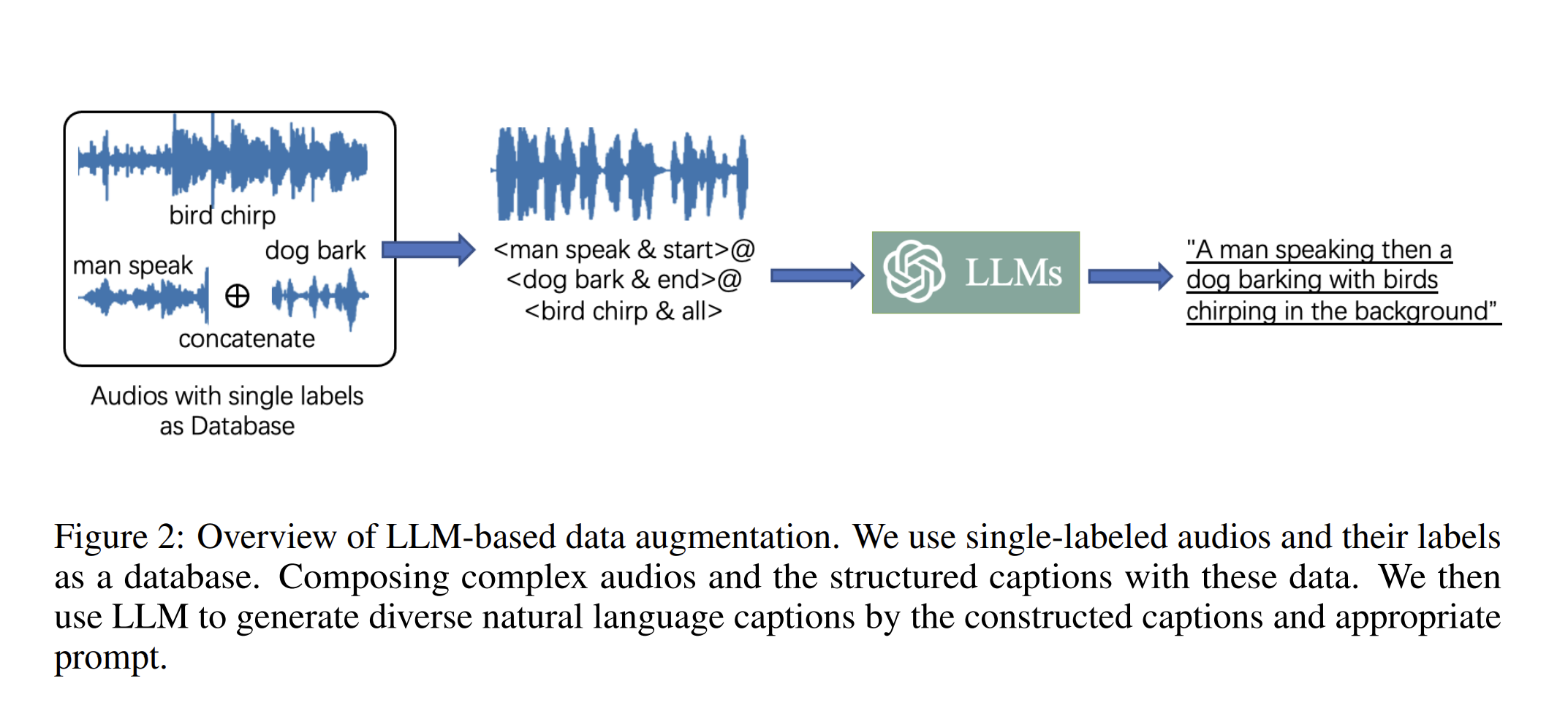
专家1给无标记音频打上标签,专家2通过生成的标签再到数据库里去找无标记的音频,这样就生成了两对结果
- 真实音频 与 预测label
- 真是label 与 预测音频
评委选择
选择CLAP分高的那个audio-text pair
CLAP可以同时做Audio-captioning和text-audio retrieval
**Tips:**这里这样做最重要的原因是作者希望能够这个text能够是自然语言,比如 先听见雨声再听见人声,通过这种数据增强的方式可以合成这两个具有先后时间关系的声音。
Dynamic Reprogramming(特殊的数据构造方式)
For verb (denoted as v), we have {‘hearing’, ‘noticing’, ‘listening to’, ‘appearing’}; for adjective (denoted as a), we have {‘clear’, ‘noisy’, ‘close-up’, ‘weird’, ‘clean’}; for noun (denoted as n), we have {‘audio’, ‘sound’, ‘voice’}; for numeral/quantifier (denoted as q), we have {‘a’, ‘the’, ‘some’};
- before v q a n of &, X
- X after v q a n of &
- etc.
通过把前面专家模型标注的数据随机填充到模版中形成新的数据
Tips:
T2A任务和TTS任务不同的是,T2A任务中文本和音频不具有时间相关性,用这个方法主要是为了构造出丰富的包含时间先后顺序的音频描述。
A high-level overview of Make-An-Audio
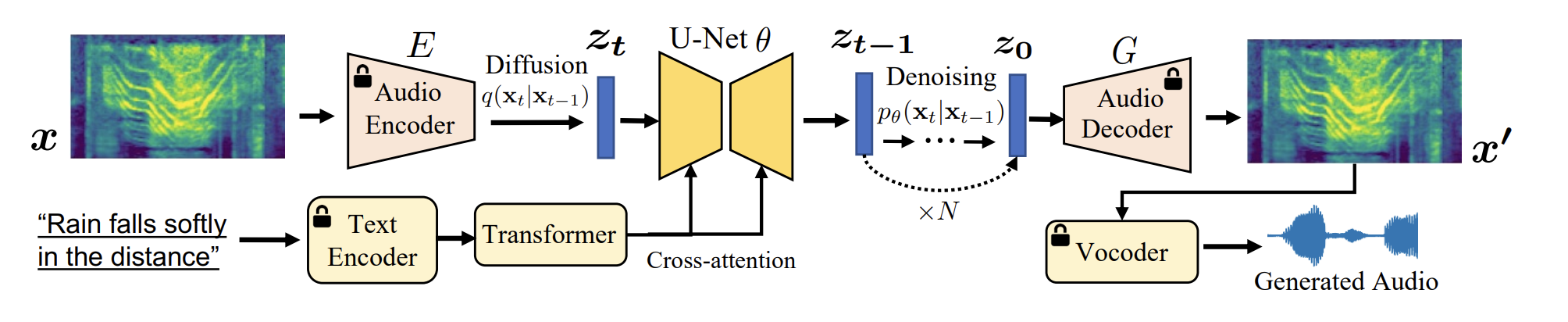
Textual Representation
文本表征部分作者尝试使用CLAP和T5(LLM)进行实验,结果发现能得到差不多的性能。
- CLAP: 通过文本和图片训练得到联合表征
- LLM: 纯文本训练
Tips:
由于CLAP无论是模型大小还是效率上都优于LLM,作者选择了使用CLAP。这里虽然作者没写,但是原因是因为任务中进行文本表征的数据被限定在一个狭小的空间中。并且CLAP作为前面专家标注模型的评委,有点自导自演的感觉了。
Audio Representation
SSAST: Self-Supervised Audio Spectrogram Transformer
没做改变 照搬结构
Tips: 把音频转化成频谱图再做表征的原因
- 频谱图从人类视觉方面更加直观且去除了相位属性
- 之前的任务已经证明了text-to-image的成功,所以尝试用文字通过生成频谱图
跟图像比较大的区别就是不具有旋转不变性,所以空间比图像来说小一些
Generative Latent Diffusion
Diffusion
GAN: weak conditional 质量可以保证 主要是多样性
Latent diffusion:
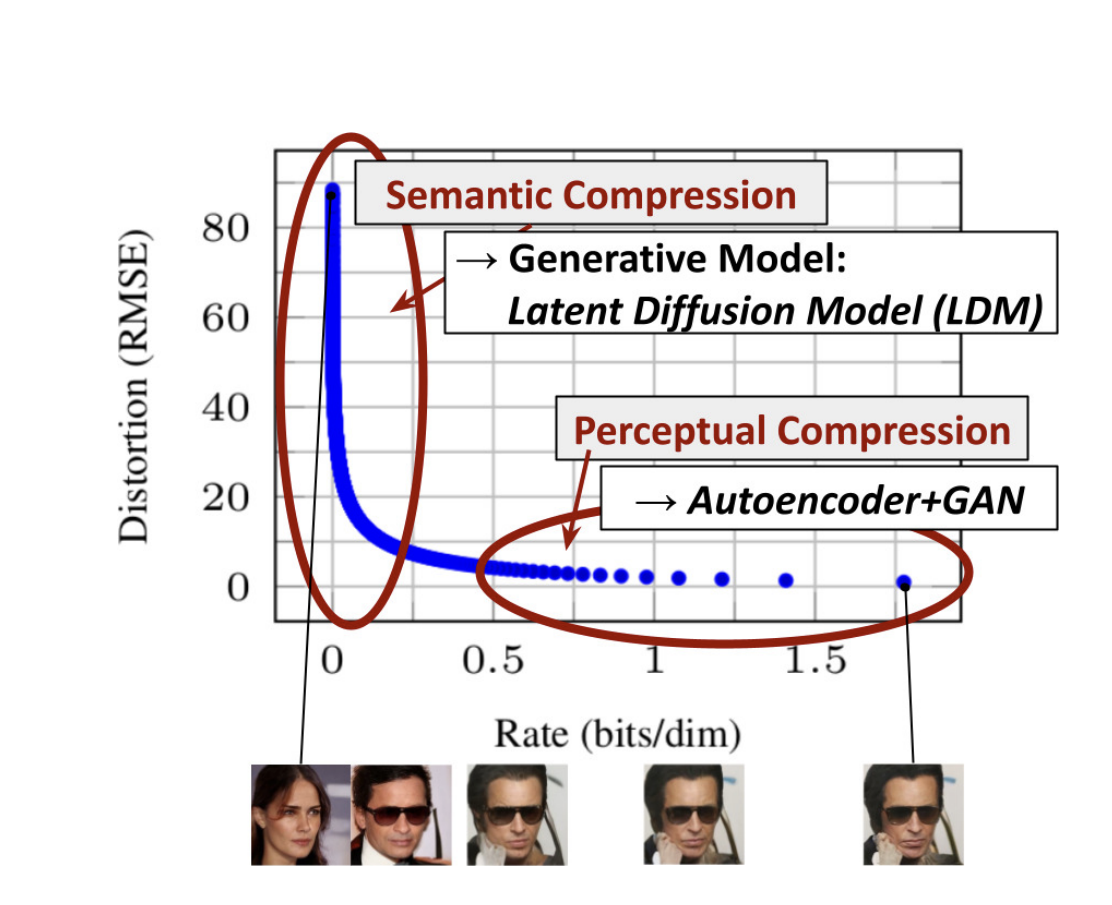
这张图解释为什么在latent space上而不是pixel上做diffusion
传统的模型浪费了一些算力和容量在人类不可感知的细节,比如像素级别的差异是区别和不敏感的。在可感知的区域用diffusion,细节上用GAN去做强conditional的任务。
这篇文章是在频谱图上面做的,可以类比图像。
U-Net: 作为diffusion去噪器
通过文本嵌入为条件,使用U-Net经过扩散过程
任务中的训练损失和DDPM相同,即使U-Net的预测噪声与采样的随机噪声的均方差损失
X-To-Audio: No Modality Left Behind
Personalized Text-To-Audio Generation
思想来源于 stochastic differential editing 随机差分编辑
个性化的音频编辑,比如有一个鸟叫声的音频,想在鸟叫的背景中加入风声,先设定一个时间步$t_0$,总去噪步骤为$N$,然后原始数据中为$t_0 \times N$加入噪声,然后去噪。
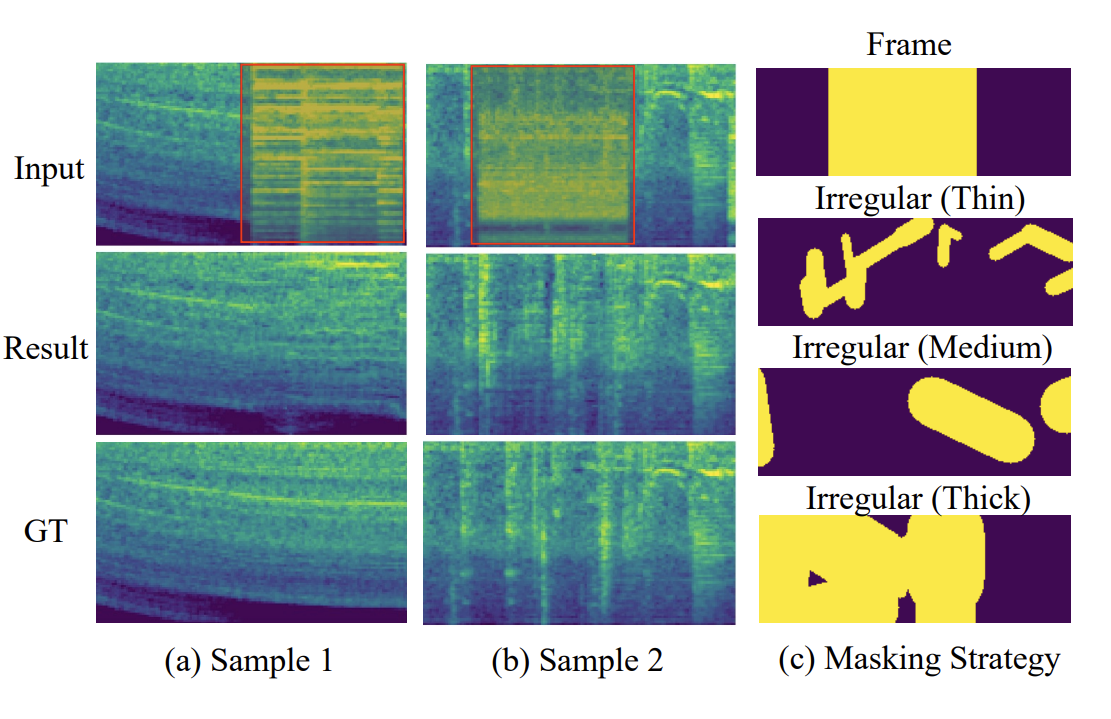
Audio Inpainting
思想来源于图像修复工作LaMa
然后基于Wav2vec2.0 做了一个基于时间域遮盖的模型
Visual(Image/Video)-to-Audio
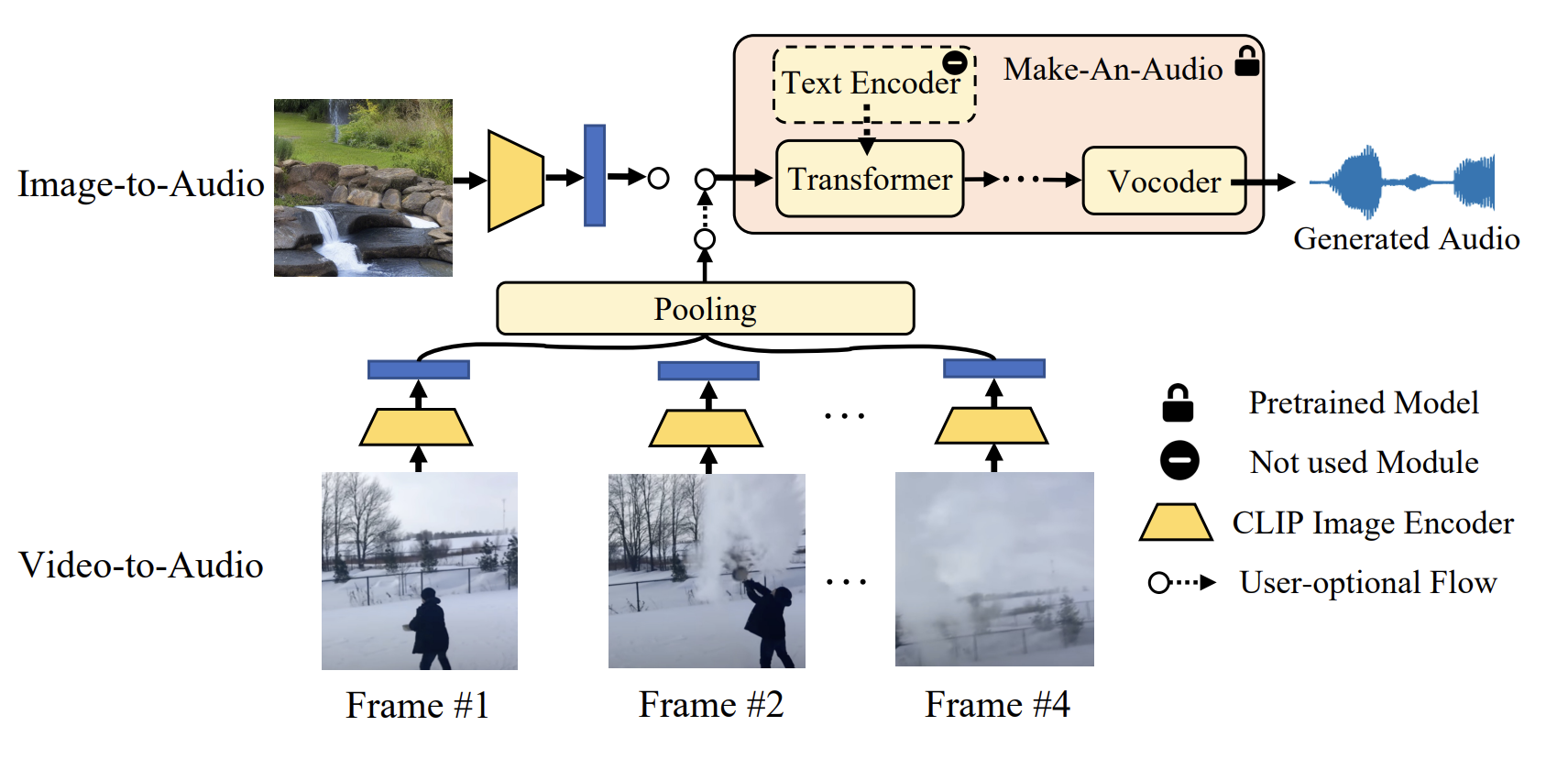
这里用的是CLIP, CLIP是一个将文本和图像映射到同一个隐空间的模型,直接用CLIP输出的图像表征去代替Text Encoder视频的话是平均抽4个帧,然后做时间维度的池化,这里有比较大的问题,比如抽不出关键帧
Make-an-audio2